
Blocco ChatGPT: ecco perche’ penso sia una mossa saggia
**For the english version, click HERE
A causa del recente provvedimento del Garante Privacy italiano, ChatGPT è stato (temporaneamente) bloccato per tutti gli utenti italiani. Ho letto molte opinioni su varie piattaforme e ho condotto un rapido sondaggio tra i miei follower su Instagram su quale fosse la loro idea, fornendo due possibili risposte:
a) “I soliti che complicano tutto”
b) “Primi!” Per qualcosa che servirà da esempio
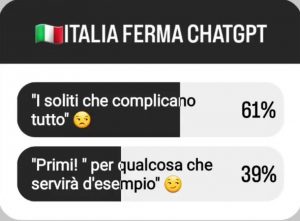
Come si evince dal sondaggio, la maggioranza ha percepito il blocco come qualcosa che dipinge l’Italia come “ostacolante” più che come un “modello da seguire”.
Io avrei votato per il secondo. Di seguito sono riportate le mie argomentazioni e alcuni ulteriori chiarimenti su quanto accaduto.
L’Azione intrappresa:
Innanzitutto partiamo da quanto evidenziato dal Garante Privacy. Il rapporto originale può essere trovato QUI. Di seguito si riporta la traduzione dei quattro motivi che hanno portato il garante ad agire:
RILEVATO, da una verifica effettuata in merito, che non viene fornita alcuna informativa agli utenti, né agli interessati i cui dati sono stati raccolti da OpenAI, L.L.C. e trattati tramite il servizio di ChatGPT;
RILEVATA l’assenza di idonea base giuridica in relazione alla raccolta dei dati personali e al loro trattamento per scopo di addestramento degli algoritmi sottesi al funzionamento di ChatGPT;
RILEVATO che il trattamento di dati personali degli interessati risulta inesatto in quanto le informazioni fornite da ChatGPT non sempre corrispondono al dato reale;
RILEVATO, inoltre, l’assenza di qualsivoglia verifica dell’età degli utenti in relazione al servizio ChatGPT che, secondo i termini pubblicati da OpenAI L.L.C., è riservato a soggetti che abbiano compiuto almeno 13 anni;
Ora, ho trovato alcuni di loro difficili da comprendere. Un esempio è quello relativo all’età dell’Utente. Pur essendo a favore di un uso responsabile, capisco le preoccupazioni di chi evidenzia una mancanza di coerenza rispetto ad altri servizi web, dove le piattaforme sono completamente accessibili attraverso un semplice clic su un pulsante che dice: “Confermo di avere più di 18 anni “.
D’altra parte, penso che un solo punto della lista sia sufficiente a motivare quanto successo. Mi riferisco al primo punto inerente alle informazioni relative agli utenti e agli interessati i cui dati sono stati raccolti da OpenAI. Prima di approfondire sul perché ritengo sufficiente questo aspetto a motivare l’azione intrapresa dal Garante Privacy, vorrei condividere qui anche la richiesta che il Garante ha rivolto ad OpenAI:
a) ai sensi dell’art. 58, par. 2, lett. f), del Regolamento dispone, in via d’urgenza, nei confronti di OpenAI L.L.C., società statunitense sviluppatrice e gestrice di ChatGPT, in qualità di titolare del trattamento dei dati personali effettuato attraverso tale applicazione, la misura della limitazione provvisoria, del trattamento dei dati personali degli interessati stabiliti nel territorio italiano;
b) la predetta limitazione ha effetto immediato a decorrere dalla data di ricezione del presente provvedimento, con riserva di ogni altra determinazione all’esito della definizione dell’istruttoria avviata sul caso.
Come evidenziato, la richiesta riguardava specificamente la limitazione del trattamento dei dati personali degli interessati. Dal mio punto di vista, questa è una richiesta diversa dal bloccare o annullare il servizio per gli utenti italiani. Quindi, perché credo che questa richiesta sia ragionevole? Perché c’è un precedente legale che coinvolge ChatGPT, datato 20 marzo 2023.
Il precedente legale:
Il 20 marzo, durante delle sessioni di chat, ad alcuni utenti di ChatGPT sono state mostrate informazioni “casuali” appartenenti ad altri utenti. Tali informazioni includevano nomi, cognomi, indirizzi e-mail, indirizzi di fatturazione e le ultime quattro cifre del metodo di pagamento utilizzato dagli utenti premium per abbonarsi al servizio.
OpenAI ha prontamente identificato e corretto il bug, e riconosciuto pubblicamente i problemi di privacy che potrebbe aver causato.
Questa storia arriva direttamente dal sito web di OpenAI. Potete leggerla qui.
Personalmente, credo nella buona fede di quanto accaduto e considero la volontà di OpenAI di informare gli utenti attraverso il proprio sito web un segno di un approccio responsabile.
Tuttavia, nonostante questo episodio, non sono ancora chiari i dettagli su come il modello è stato (è) addestrato e quali informazioni vengono raccolte dalle interazioni con gli utenti attraverso il servizio Chat. Nel GPT technical report, un’informazione che ho trovato utile è la seguente:
GPT-4 generally lacks knowledge of events that have occurred after the vast majority of its pre-training
data cuts off in September 2021, and does not learn from its experience.
Tuttavia, non sono stato in grado di acquisire ulteriori dettagli sulla raccolta o sull’utilizzo dei dati.
Cosa ne penso?:
In qualità di ingegnere di intelligenza artificiale, so perfettamente che un bug è un bug e alcuni di essi sono difficili da catturare in anticipo nonostante i migliori sforzi ingegneristici. Non incolpo nessuno e presumo la buona fede quando accadono cose del genere.
Partendo da questa premessa, dopo aver letto il racconto pubblicato sul loro sito, mi sono posto alcune domande:
- Hanno identificato la perdita di informazioni perché includeva i nomi e i cognomi degli utenti premium. Sarebbero in grado di identificare un’ipotetica fuga di altri tipi di informazioni che non contengono nomi o riferimenti diretti? Ad esempio, se chiedessi all’IA informazioni relative a un argomento che mi interessa e quella parte dello scambio (comprese domande e risposte) apparisse casualmente nella chat di qualcun altro, sarebbero comunque in grado di identificare la fonte e la perdita?
- E se le informazioni trapelate appartenessero alla mia azienda (in caso ne avessi una)?
- Tra le informazioni trapelate c’erano indirizzi di pagamento. Di solito, quelli corrispondono a edifici/case fisiche. Come si sara’ sentita la persona che ha subito questa condivisione non permessa? come mi sentirei io, se succedesse a me?
- Cosa accadrebbe se informazioni più dettagliate trapelassero di nuovo per qualche altro bug non ancora identificato?
Queste domande mi hanno fatto riflettere di più sul ruolo della Privacy nell’era delle identità digitali.
Tornando al Garante della Privacy, l’ente ha chiesto trasparenza su come le informazioni appartenenti agli utenti (ad esempio, i testi delle sessioni di chat) sono trattate e conservate. Questo è allineato con quanto stabilito dall’art. 5 del GDPR, che -nei primi tre punti- recita:
I dati personali sono:
a) trattati in modo lecito, corretto e trasparente nei confronti dell’interessato (“liceità, correttezza e trasparenza”);
b) raccolti per finalità determinate, esplicite e legittime, e successivamente trattati in modo non incompatibile con tali finalità; l’ulteriore trattamento di dati personali a fini di archiviazione nel pubblico interesse, di ricerca scientifica o storica o a fini statistici non è, ai sensi dell’articolo 89, paragrafo 1, considerato incompatibile con le finalità iniziali (“limitazione delle finalità”);
c) adeguati, pertinenti e limitati a quanto necessario rispetto alle finalità per le quali sono trattati (“minimizzazione dei dati”);
Questi punti sono estremamente importanti per comprendere quanto affermato nella relazione del Garante Privacy.
A prescindere da qualsiasi definizione sul compito specifico del Garante Privacy, credo che esso svolga anche un ruolo di PREVENZIONE. Fare prevenzione significa che l’istituzione dovrebbe essere in grado di anticipare le minacce mentre comportano solo un rischio, prima che si trasformino in qualcosa che può causare danni. Idealmente, qualsiasi intervento dovrebbe essere impeccabile, ma usando il buon senso, è giusto presumere che in alcuni casi possano verificarsi errori in buona fede. Nelle fasi di prevenzione, gli unici errori accettabili sono quelli relativi ai falsi positivi rispetto ai falsi negativi: meglio far suonare l’allarme antincendio quando c’è solo fumo in giro che attivarlo quando mezza casa è già bruciata!
Per questo ritengo giustificato l’intervento del Garante Privacy e lo vedo come qualcosa da prendere come riferimento o modello in termini di sensibilità utilizzata per cogliere l’ipotetico rischio.
Il punto chiave (inaspettato):
A questo punto, dovrebbe essere chiaro che considero l’intera situazione come una pratica “business as usual” senza colpe o cattiva volontà da parte di nessuno degli attori coinvolti. Personalmente, non riesco ancora a capire appieno perché il 61% delle persone che hanno partecipato al mio sondaggio su Instagram pensa che questo intervento sia negativo.
Consultando altre fonti come il forum sul sito Web di ChatGPT, l’articolo dalla stampa, i social media, una delle principali obiezioni è che tali interventi non promuoverebbero l’innovazione in Italia. Leggi e regolamenti fanno già parte di qualsiasi processo di progettazione di nuovi prodotti. Che si parli di auto, vestiti o succo d’arancia, ogni segmento di mercato deve rispettare le normative applicabili e non dovrebbe essere fatta alcuna differenza per l’IA.
L’intelligenza artificiale è una tecnologia molto potente e credo nei vantaggi della sua adozione. Tuttavia, allo stesso tempo, riconosco quanto sia delicata e cruciale la componente “Dati”, da qui il bisogno di sensibilità nell’individuare i potenziali rischi correlati al loro trattamento.
Questa situazione mi ha portato a mettere in discussione il livello di priorità che gli utenti finali danno alla propria privacy. Quanto è interessato a proteggere la propria Privacy l’utente medio? Qual è il livello di consapevolezza sui possibili rischi?
In altre parole, la mia ipotesi è che i recenti provvedimenti presi dal Garante della Privacy italiano siano considerati negativi o di ostacolo all’innovazione, non perché le persone abbiano una cieca fiducia nella tecnologia, ma perché attribuiscono diversa (minore) importanza alle questioni relative alla Privacy. Questo aspetto è quello che mi preoccupa di più perché, come ho condiviso durante il mio TED-Talk, penso che un’adozione responsabile e di successo dell’IA dipenda tanto da chi crea le applicazioni quanto da chi poi le usa.
Andando avanti mi aspetterei sempre più interazioni tra il mondo della tecnologia e quello legale, perché una vera innovazione può avvenire solo quando i due mondi vanno di pari passo. Tuttavia, credo che questo episodio stia generando un sano dibattito sulla privacy che (si spera) aumenterà la consapevolezza e aiuterà a strutturare il percorso per accelerare l’innovazione in futuro.
Bisogno di Trasparenza:
Il 3 aprile 2023, The Economist Korea ha riportato tre esempi separati di dipendenti Samsung che hanno involontariamente divulgato informazioni sensibili a ChatGPT. In un caso, un dipendente ha incollato un codice sorgente riservato nella chat per verificare la presenza di errori. Un altro dipendente ha condiviso il codice con ChatGPT e “ha richiesto l’ottimizzazione del codice”. Un terzo ha condiviso una registrazione di una riunione da convertire in note per una presentazione. Come affermato dalla fonte di questa notizia, “queste informazioni sono ora disponibili per nutrire ChatGPT”.
Questa è un’altra storia che evidenzia la necessità di ottenere trasparenza su quali dati vengono raccolti, come vengono utilizzati e di lasciare il controllo delle informazioni personali a proprietari.
Sintesi delle conclusioni:
Ritengo che l’azione intrapresa dal Garante Privacy italiano sia positiva e dimostri il giusto livello di sensibilità richiesto dalla materia.
- Come riportato dalla stessa OpenAI, esiste un precedente legale che coinvolge “la fuoriuscita dei dati” su ChatGPT, la condivisione di nomi, cognomi, indirizzi email e indirizzi fisici di alcuni utenti, in sessioni di chat di altri utenti.
Esito: la richiesta del Garante era di interrompere il trattamento dei dati dell’utente. Non mi è ancora chiaro come/perché questa richiesta si sia tradotta nel divieto del servizio.
Trasparenza: essere in grado di spiegare come e perché le informazioni vengono raccolte da uno strumento, è obbligatorio ai sensi del GDPR. La stessa mancanza di trasparenza ha portato alla fuga di informazioni di Samsung, recentemente segnalata.
- Innovazione: costruire un prodotto da solo non basta. Ogni prodotto che arriva sul mercato deve rispettare le normative in vigore che si applicano alla categoria specifica (GDPR in questo caso). Nessuna eccezione è stata fatta qui.
Prevenzione: quando si previene, i falsi positivi sono meglio dei falsi negativi. I falsi allarmi sono meglio della corsa alle soluzioni quando è troppo tardi. Mi aspetto qualche attività di prevenzione dal ruolo di Garante Privacy.
Ottima esperienza: questo episodio sta generando un sano dibattito sulla privacy che può aiutare i non esperti e aumentare la consapevolezza tra gli utenti finali.
Se hai trovato utile questo articolo, ti invito a visionare altri contenuti sul mio profilo instagram.