
ChatGPT ban: Why I believe it was a wise move
**Per la versione Italiana del post, clicca QUI
Due to the recent action taken by the Italian Privacy Guarantor, ChatGPT has been (temporarily) blocked for all Italian users.
I have read a lot of opinions on various platform and run a quick survey on my followers on Instagram on what their idea was, providing two possible answers:
a) “Italy bureaucracy blocks everything as usual”
b) “First!” For something that will serve as a role model
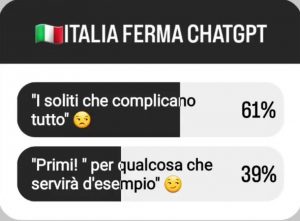
As captured by the survey, the majority have perceived the block as something that depicts Italy as a “blocker” more than a “role model”.
I would have voted for the second. Below are my arguments and some additional clarifications on what’s happened.
The Action:
First of all, let’s start with what was highlighted by the Privacy Guarantor. The Original report can be found HERE. Below is a translation of the four reasons that brought the guarantor to take action:
DETECTED, from a check carried out in this regard, that no information is provided to users, nor to interested parties whose data has been collected by OpenAI, L.L.C. and processed through the ChatGPT service;
NOTING the absence of an appropriate legal basis in relation to the collection of personal data and their processing for the purpose of training the algorithms underlying the functioning of ChatGPT;
NOTING that the processing of personal data of the interested parties is inaccurate as the information provided by ChatGPT does not always correspond to the real data;
DETECTED, moreover, the absence of any verification of the age of users in relation to the ChatGPT service which, according to the terms published by OpenAI L.L.C., is reserved for individuals who are at least 13 years old;
Now, I found some of them challenging to understand. An example is the one related to the User’s age. While I’m in favor of responsible use, I understand the concerns of whom highlights a lack of consistency compared to other web services, where platforms are fully accessible through a simple click on a button saying, “I confirm I am 18+ years old”.
On the other side, I think one bullet on the list is worth the action. I’m referring to the first bullet related to the information related to users and interested parties whose data has been collected by OpenAI. Before diving into why I believe this aspect is enough to motivate the action taken by the Privacy Guarantor, I would like to share here also the request that the Guarantor made to OpenAI:
a) pursuant to art. 58, par. 2, lit. f), of the Regulation, urgently establishes, against OpenAI L.L.C., a US company that develops and manages ChatGPT, as owner of the processing of personal data carried out through this application, the measure of the temporary limitation of the processing of personal data of data subjects established in the Italian territory;
b) the aforementioned limitation has immediate effect from the date of receipt of this provision, subject to any other determination following the outcome of the definition of the investigation started on the case.
As highlighted, the request was specifically on limiting the processing of personal data belonging to subjects and explain how user’s data are being used. From my perspective, this is a different request to block or cancel the service for Italian users.
So, why do I believe that this request is reasonable? Because there is a legal precedent that involves ChatGPT, dated March the 20th 2023.
The Legal Precedent:
On March 20th, some users of ChatGPT got provided information belonging to other users in their chat. Those information included Names, Last Names, Email addresses, Payment addresses, and the last four digits of the payment method premium users used to subscribe to the service.
OpenAI has promptly identified and fixed the bug and publicly acknowledged the Privacy issue it might have caused.
This story comes directly from the OpenAI website. You can read it HERE.
I genuinely believe in good faith for what happened, and I consider OpenAI’s willingness to inform the users through their website a sign of a responsible approach.
Despite this episode, the details about how the model was (is) trained and what information is being collected from interactions with users through the Chat service are still not clear. In the GPT technical report, one piece of information I found helpful is the following:
GPT-4 generally lacks knowledge of events that have occurred after the vast majority of its pre-training
data cuts off in September 2021, and does not learn from its experience.
However, I wasn’t able to capture additional details on data collection or usage.
Need for transparency:
On April 3rd 2023, The Economist Korea reported three separate examples of Samsung employees unintentionally leaking sensitive information to ChatGPT. In one case, an employee pasted confidential source code into the chat to check for errors. Another employee shared code with ChatGPT and “requested code optimization.” A third, shared a recording of a meeting to convert into notes for a presentation. As stated by the source of this news, ” that information is now out in the wild for ChatGPT to feed on”.
This is another story that highlights the need to get transparency on what data are being collected, how they are being used and leave control of personal information back to the owner.
My thoughts:
As an AI engineer, I perfectly know that a bug is a bug, and some of them are difficult to capture in advance despite the best engineering efforts. I don’t blame anybody and assume good faith when things like this happen.
Using this as a premise, after reading the story published on their website, I asked myself a few questions:
- They identified the information leakage because it included the names and last names of premium users. Could they capture a leakage of other types of information that wouldn’t contain any names or direct references? For example, If I would ask the AI for information related to a topic that is keen for me, and that part of the exchange (including questions and answers) appears randomly in someone else chat, would they still be able to identify the source of the leak?
- What if the leaked information belonged to my company (If I had one)?
- Among the leaked information, there were payment addresses. Usually, those correspond to physical buildings/houses. What would happen if that information were mine?
- What would happen if more detailed information leaked again for some other bug not yet identified?
These questions made me think more about the role of Privacy in the era of digital identities.
Back to the Privacy Guarantor, they asked to have transparency on how the information belonging to users (for example, text from the chat sessions) was processed and stored. This is captured by Art. 5 of GDPR, which -in the first three bullets- states:
Personal data are:
a) processed in a lawful, correct and transparent manner in relation to the data subject (“lawfulness, correctness and transparency”);
b) collected for specified, explicit and legitimate purposes, and not further processed in a way that is incompatible with those purposes; further processing of personal data for archiving purposes in the public interest, scientific or historical research purposes or statistical purposes is not, in accordance with Article 89(1), considered to be incompatible with the initial purposes (“purpose limitation”);
c) adequate, relevant and limited to what is necessary in relation to the purposes for which they are processed (“data minimisation”);
These bullets are extremely important to understand what was stated in the report of the Privacy Guarantor.
Regardless of any definition of the specific duty of the Privacy Guarantor, I believe that it also plays a role in PREVENTING things from happening. Doing prevention means that the institution should be able to anticipate threats while they only carry a risk before they turn into something that can cause damage. Ideally, any intervention should be impeccable, but using common sense, it’s fair to assume that good-faith mistakes- might occur in some cases. In the prevention phases, the only acceptable mistakes are related to false positives over false negatives: better to play the fire alarm when there is smoke around than miss out on playing it when half of the house is already burned!
This is why I consider the intervention of the Privacy Guarantor justified and something that should be taken as a reference or role model in terms of sensitivity used to capture the hypothetical risk.
The (unexpected) Key-aspect:
At this point, it should be clear that I see the whole situation as a “business-as-usual” practice whit no faults or bad willingness from any of the parties. I’m still unable to fully understand why 61% of the people who took my Instagram survey think this intervention is negative.
By consulting other sources like the forum on ChatGPT website, Article from press, social media, one major objection is that such interventions are not fostering innovation in Italy. Laws and regulations are already part of any design process for new products. Whether we talk about cars, clothes, or orange juice, each market segment needs to comply with applicable regulations and no difference should be made for AI.
AI is such a powerful technology, and I can see the benefits of its adoption. Still, at the same time, I recognize how delicate and crucial is the Data component, hence the need for sensitivity in identifying potential risks.
This situation led me to question the level of priority that end-users might have on their own privacy. How keen on protecting its own Privacy is the average user? What is the level of awareness about the possible risks?
In other words, my hypothesis is that the recent action taken by the Italian Privacy Guarantor are considered negative or an obstacle to innovation, not because people have blind faith in technology, but because the give different (less) importance to Privacy related matters. This aspect is what concerns me the most because, as I shared during my TED-Talk, I think that a successful and responsible adoption of AI, depends on who builds applications as much as on end-users.
Moving forward I would expect more and more interactions happening between the Technology world and the Legal one, because proper innovation can only happen when the two goes hand-in-hand. Nonetheless, I believe this episode is generating a healthy debate around Privacy that will (hopefully) increase awareness and help structure the route to accelerate innovation in the future.
Conclusions summary:
- I believe that the action taken by the Italian Privacy Guarantor is positive and demonstrates the right level of sensitivity required by the matters.
- As reported by OpenAI itself, there is a legal-precedent involving “data outage” on ChatGPT, sharing names, last names, email addresses, and physical addresses of some users into chat sessions with different users.
- Outcome: request from the Guarantor was to stop the processing of user’s data. It’s still unclear to me how/why this request translated into forbidding the service.
- Transparency: being able to explain how and why information are being collected by a tool, is mandatory under GDPR. Same lack of transparency led to the Samsung leak, recently reported.
- Innovation: building a product itself is not enough. Every product getting to market needs to comply with regulations in place that apply to the specific category (GDPR in this case). No exception was done here.
- Prevention: when preventing, false-positives are better than false-negative. False alarms are better than rushes to solutions when it’s too late. I expect some prevention activity from the Privacy Guarantor role.
- Eealthy experience: This episode is generating a healthy debate around privacy that can benefits non-experts and increase awareness among end-users.