At the META Connect event 2023, Mark Zuckerberg announced the introduction of “virtual assistants” on WhatsApp, Messenger, and Instagram. This news left me with more question marks than excitement because going beyond META itself as a company, I started questioning myself whether we, as “Humans” end-users are actually ready to have “generalists” chatbots in the palm of our hands. Therefore, I decided to learn more about META’s new feature and the topic in general.
Thanks to this exercise I learned about META’s best efforts to build Generative AI Features responsibly and their commitment to Privacy.However, few questions still need to be answered, and overall, my excitement didn’t really improve. I came to the conclusion that the current trend (not limited to META) of designing chatbots with personalities and background story, might work in the opposite direction of all the filtering systems that are being added to these tools to limit unwanted interactions.
The difference between the tool and a human interaction should be constantly highlighted as I think it would help people developing a healthier level of trust in the tools, contributing to a more responsible and less harmful use of this technology. I see the value of AI in general and these tools for accelerating everyday routines. On the other side, I see no value but superficial, compared to the “risk” the end user might face in having a “digital assistant” pretending to be our best friend while gossiping our intimate information to third-parties.
In this article, I will share what I have learned on the topic, highlight the open questions that I believe should be addressed before adopting such tools, discuss some concerns, and propose new directions to drive more responsible adoption.
The Announcement:
META will soon introduce “virtual assistants” on WhatsApp, Messenger and Instagram. The “characters” will have different personalities, interests, opinions and background stories.
Apparently, the goal of these characters is to stimulate conversations with users for a more “immersive” interaction. Talking to them “should feel like talking to familiar people”.
Ideally, users will include these virtual assistants in “group chat” or as direct contact to interact with. When added to groups, it can help organize events by retrieving information when asked to.
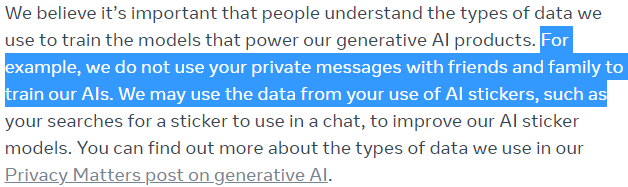
Information are expected to stay within the specific app, and not share with other users. Whether the learning from an interaction with a specific user will benefit other user’s chat is still unclear.
Chat between users, family and friends will remain private and encrypted. Messages exchanged with the “Character” may be used for improving the service, meaning for re-training the AI model.
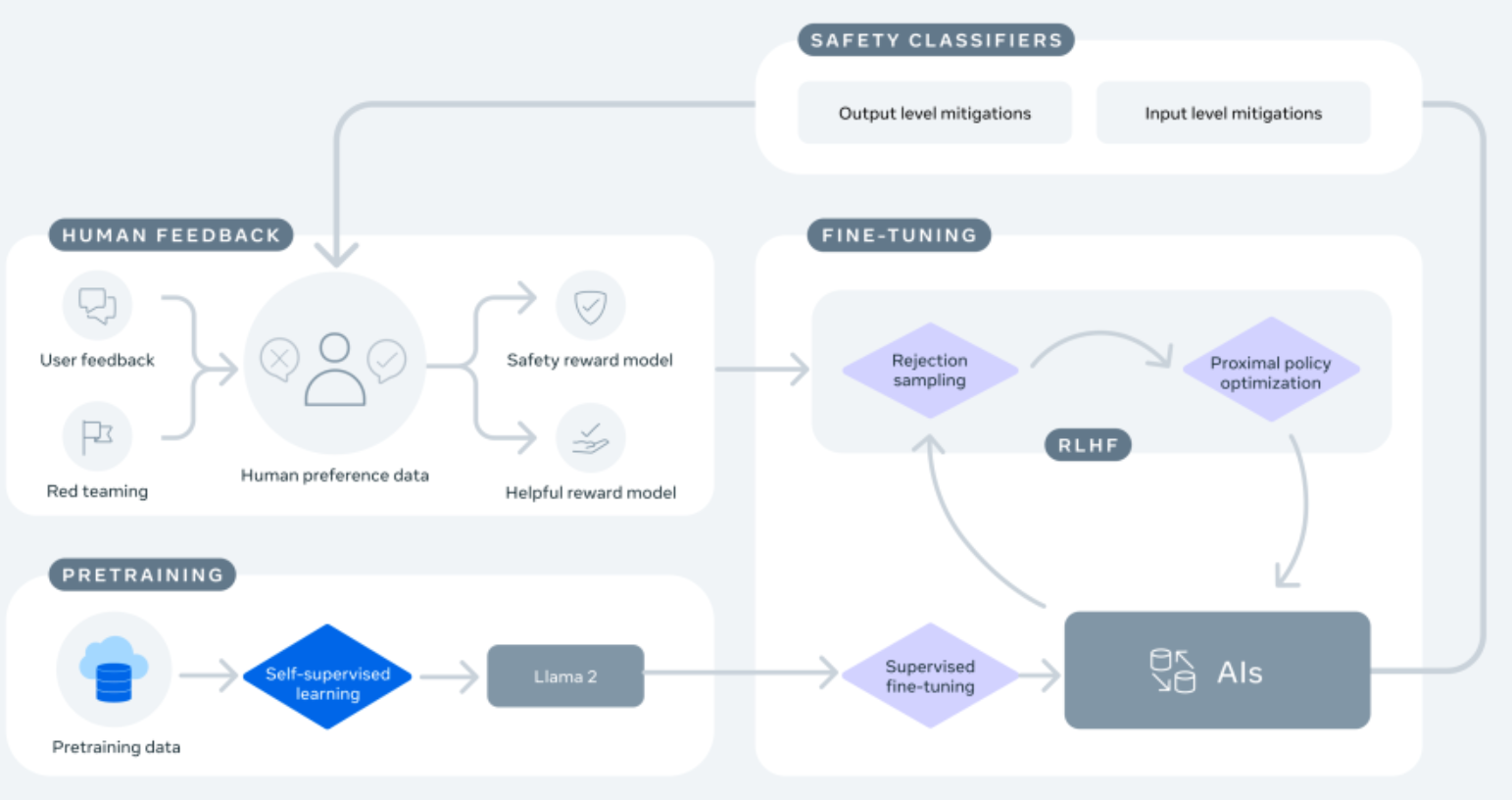
As you can see, the “Human Feedback” block provides and essential part of data to train and fine-tune the model. This means that interactions are not only the final goal of the service but also the critical aspect for collecting data to keep evolving it.
Open questions:
Based on what I learned on the META website, below is the list of questions that I formulated when I first read about the announcement. Further down below, I report the questions that have been answered by the info retrieved on the META website:
Q1) What are the benefits for the end-users to be incentivized to longer interactions with human-like chatbots?
Q2) Will all the chats with the virtual assistant be used? If yes, for how long? Will the user be able to opt-out from having the chat used, or is it implicit that to avoid data collection, the only option will be not to leverage the service at all?
Q3) What happens if all the META users start to ask the virtual assistant to seek for information instead of leveraging search engines: would that impact the free market? If yes, how and what alternatives will end-users and new start-up have?
Q4) How is META able to provide such services for FREE?
Q5) What are the risks (including unwanted answers or inappropriate conversations) associated with such services?
Answered questions:
The questions for which I was able to find answers are the following: Q7) When people interact over WhatsApp, Messenger, or Instagram, the conversations are encrypted. What would happen in this case where the interlocutor would be the same entity responsible for encrypting the exchanges?
As stated on the META website (and reported in Figures 4a, 4b, and 5), only the user interactions with the chatbot will be used to re-train the model. Hence, we should expect any questions or conversations we will have with the chatbot to be shared to improve the model.
Q8) What measures (if any) are in place to mitigate the dangerous unwanted effects?
At this point I envision 3 major areas of concerns related to Privacy, Safety and Business. It is important to note that the following considerations are not specifically related to the META product but to the overall idea of having “chatbots” to interact with at a general level, in the palm of user’s hands.
Privacy concerns:
In March 2023, the Italian Privacy Guarantor blocked ChatGPT reporting – among the causes – the lack of transparency on how the system used data from user interactions. While it is clear that META will leverage users’s information to re-train the model and improve the service, determining the level of control (if any) the user will have over its data after being collected is still unclear. The only paragraph I was able to retrieve on this part on the META documentation is reported in Fig. 3b. While Fig. 3b shares tips on how a user will be able to delete a chat, there is no clear indication of how deleted messages will impact the model. Will it remember what it has learned from an interaction after a user has deleted it? What level of control will the user have on the entire data flow?
When it comes to LLMs (Large Language Models), the current state of the art says that information used to train the model can’t be forgotten unless the model get re-trained from scratch without the selected information. Despite regulators have already discussed about “the right to be forgotten”, for which additional details and proposed solutions can be found HERE, there is still a lot of skepticism. It would be like aiming at remove the salt from a sauce after it was cooked and blended together: the only way to be sure there is no salt, is to remake the sauce from scratch without the ingredient.
These considerations become even more critical if we consider that a recent study has shown how LLMs are capable of capturing information about their interlocutor even when not directly expressed.
Safety concerns:
Recently a man from Belgium, committed suicide after chatting with an AI system. The machine seems to have influenced the user to end his life instead of suggesting to look for help. You can read more HERE. The man was a father of two and had a healthy job but was concerned about climate change. According to his Wife, her husband started interacting with the AI on the topic, but instead of finding hope, he seemed to have lost faith. A critical sentence reported in a Euronews article, mentions:
Consequently, he started seeing her as a sentient being and the lines between AI and human interactions became increasingly blurred until he couldn’t tell the difference.
While I appreciate META’s efforts to learn from these experiences and adopt a responsible approach (as stated HERE and confirmed by Fig. 6), I have a few concerns about the complexity of the task that needs to be addressed. Machines can leverage human language to communicate but (still) lack the reasoning ability that would help to limit these cases. AI is able to generate text but does not know the difference between true and false or right from wrong. AI just know how to build meaningful sequences of words that are more or less related to the original queries. From this perspective, words can be used to express an infinite number of concepts. The larger the model, the more words and concepts it can generate. META virtual assistant seems to be extremely inclusive and leverages these large language models. However, there is no guarantee nor risk esteem that can help end users identify the level of maturity or reliability of these systems.
The most critical aspect in what happened in Belgium is not related to the inability of the tool to filter out delicate questions, as it is on the human that has empathized with the tool. Empathizing is a human ability. It did not happen only in this case. How many people developed a kind of attachment with their first ever owned car? Or house? or cologne? or phone? Among humans, empathizing is a super-power because it facilitate the process of building relationships. Now this super-power might turn into a super-weakness if it leads us to forget the artificial nature of the AI system we might be interacting with. It is like if cars were designed with dashboards that would require 3 hands but a single driver to be properly maneuvered: humans would be penalized by their nature (only 2 hands) and risk of accidents would increase. The fact that these AI tools are being designed to close the perceptive gaps and blur the line between what’s synthetic and what’s human, might generate more risks than opportunity for healthy interactions in the long run. In this case it was an Adult, father of two, with a solid career and focused on a specific topic. Still, none of these aspect helped in avoiding the tragedy. What would happen if we put kids, with all their limitless curiosity and low experience in dealing with boundaries on the other side of the chat with an AI based tool purposely designed to “be friendly”?
Examples of unwanted or dangerous answers from LLMs are multiple and do not stop at the sad Belgian story. Below are some additional key references:
AI-generated guides to edible plants (sold on Amazon) encouraged readers to gather poisonous mushrooms. Online sleuths have found dangerous misidentifications. LINK
A New Zealand supermarket chain offered a chatbot that makes recipes from lists of ingredients. When a user asked it what to do with water, ammonia, and bleach, it offered a recipe for lethal chloramine gas. Subsequently the bot appended recipes with the disclaimer, “You must use your own judgment before relying on or making any recipe produced by Savey Meal-bot.” LINK
A chatbot provided by the National Eating Disorder Association dispensed advice likely to exacerbate eating disorders, users reported. For instance, it told one user with anorexia to continue to lose weight. The organization withdrew the bot. LINK
META reassured on their procedures which includes more advanced and extended testing phases, however I wonder if trial-errors approach are effective enough to capture the whole space of possible answers where the chatbot can be (harmfully) wrong. These doubt are even more amplified when I think outside the META perimeter and include all the “generalists” chatbots. What would happen if questions arose that were not previously tested?
For example, what if a teenager is seeking private support on a presumed pregnancy? What is the likelihood of having a non-harming response from the chatbot? Will this information be used to provide targeted advertisements?
As of today, I believe that these chatbots provide most value when limited to a specific context (i.e. contextualized vocabularies or jargon) for two reasons:
The space of possible answers, including the wrong ones, is limited to a specific context
They are there to support user requests and are not necessarily tuned to stimulate longer interactions. Hence, no need for “characterizations” of the tools
Business concerns:
Providing “chatbots” or – more in general – LLM based services is extremely expensive: it requires the cost of implementing and maintaining software in addition to dedicated computing and high energy bills. This has also been highlighted by Microsoft seeking cheaper alternatives to ChatGPT and OpenAI – which has recently started investigating ways to save money.
So, what is the business models that META envisions to get a return from this investment? Here is my hypothesis:
META sees its value in owning users’ data that can be sold for advertisement. This new feature will work on the same line but will provide a much more granular view of the user’s preferences. For businesses interested in buying information and statistics around users preferences on a specific topic or category of interest, it will be like talking to our best friend to get as close as possible to our decision-making process. I expect this to be a massive disruptor of the market for two reasons:
If People will start asking the assistants to retrieve information on their behalf, who will use the search engines anymore? Will the chatbot redirect answers to paid insertions?
What about the monopoly that META will be able to build around user’s data? Thanks to this new service, META might gain a huge market advantage making the life of any hypothetical competitive start-up or business extremely tough. While I recognize it would all be the outcome of a winning strategy, I wonder if it could also be a discussion point for regulators. Unfortunately, I am not a subject matter expert, therefore I can only go as far as I did in formulating the question.
My thoughts:
As an AI engineer, I am well aware that processes need time to improve. I am also excited to see AI becoming useful and helping a lot of people with everyday routines. However, I am not in favour of speeding things up at all cost for the sake of excitement. Especially when it comes to AI, where I would instead use a cautious approach. This technology is meant to help humans, and I believe the top priorities should focus on developing higher awareness among users and ensure that proper regulations are in place before dropping advanced technology into anyone’s pocket.
If we combine the concerns described above with the way these virtual assistants have been developed, the picture seems to be less appealing.
As stated by META (Fig. 2), the virtual assistants were developed to give the impression that we will interact with “familiar people”. This translates to the objective of getting as close as they can to the user’s life to stimulate intimate conversations and long-lasting interactions. I consider this extremely hazardous.
To give an example, generally speaking, I love Do-It-Yourself activities, but there are equipment like chainsaws for which a license or a training course is required before using them. Where a license is not needed, common-sense is expected. Like when dealing with powered electrical devices and water proximity. Do we have similar guidelines for these AI tools? Because they can generate unwanted effects too, especially if used by kids and non-experts. Perhaps introducing a license or a small training course on “approaching AI on a daily basis” could already represent a solution toward a more responsible approach for end-users.
Conclusions summary:
Summarizing the big picture, here are the key bullets:
Virtual Assistants are designed to stimulate long-lasting and confidential conversations with you to maximize the interactional time on the platform hosting the service.
META’s ways of monetization are unclear. However, it appears the service is going to be free for the end-users despite being extremely expensive to offer
The effectiveness of filters and the level of risk associated with the service for the end-users are not measurable, but they differ from zero.
In conclusion, in addition to all the concerns shared regarding the status of weak awareness of the majority of the end-users, I remain skeptical about the effective value of having these virtual assistant “characterized”. Nonetheless, I personally perceive this attempt to “humanize tools” as a signal to not trust the assistants because of their “double-faced” expected attitude: best friends to you and pricy gossipers to whomever is willing to pay to learn about you.