Durante l’evento META Connect 2023, Mark Zuckerberg ha annunciato l’introduzione di “assistenti virtuali” su WhatsApp, Messenger e Instagram. Questa notizia mi ha lasciato con più domande che entusiasmo, poiché oltre a META come azienda, mi sono chiesto se noi, come utenti finali “umani”, siamo davvero pronti ad avere chatbot “generalisti” nel palmo delle nostre mani. Ho deciso quindi di approfondire la nuova funzione di META e l’argomento in generale.
Grazie a questo esercizio, ho appreso degli sforzi di META nel costruire funzionalità di intelligenza artificiale generativa in modo responsabile e del loro impegno per la privacy. Tuttavia, alcune domande restano senza risposta e nel complesso, il mio entusiasmo non è migliorato molto. Sono giunto alla conclusione che la tendenza attuale (non limitata a META) di progettare chatbot con personalità e caratterizzazioni, potrebbe funzionare nella direzione opposta dei vari sistemi di filtraggio che vengono aggiunti a questi strumenti per limitare le interazioni indesiderate.
La differenza tra lo strumento e un’interazione umana dovrebbe essere costantemente evidenziata, poiché penso che ciò aiuterebbe le persone a sviluppare un livello più sano di fiducia negli strumenti, contribuendo a un uso più responsabile e meno dannoso di questa tecnologia. Vedo il valore dell’IA in generale e di questi strumenti per accelerare le routine quotidiane. D’altro canto, non vedo alcun valore se non superficiale, rispetto al “rischio” che l’utente finale potrebbe affrontare nel avere un “assistente digitale” che finge di essere il nostro migliore amico mentre divulga le nostre informazioni intime a terzi.
In questo articolo, condividerò ciò che ho appreso sull’argomento, metterò in luce le domande aperte che ritengo debbano essere affrontate prima di adottare tali strumenti, discuterò alcune preoccupazioni e proporrò nuove direzioni per guidare un’adozione più responsabile.
L’Annuncio:
META introdurrà presto “assistenti virtuali” su WhatsApp, Messenger e Instagram. I “personaggi” avranno personalità, interessi, opinioni e storie di background diverse.
Apparentemente, l’obiettivo di questi personaggi è stimolare conversazioni con gli utenti per un’interazione più “immersiva”. Parlare con loro “dovrebbe sembrare di parlare con persone familiari”.
Idealmente, gli utenti includeranno questi assistenti virtuali in “chat di gruppo” o come contatto diretto per interagire con loro. Quando vengono aggiunti ai gruppi, possono aiutare a organizzare eventi recuperando informazioni quando richiesto.
Le informazioni dovrebbero rimanere all’interno dell’app specifica e non condivise con altri utenti. Se l’apprendimento da un’interazione con un utente specifico beneficerà altre conversazioni degli utenti è ancora incerto.
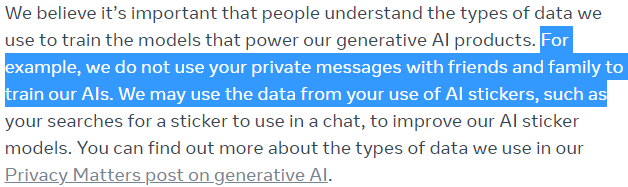
Le conversazioni tra utenti, familiari e amici rimarranno private ed criptate. I messaggi scambiati con il “Personaggio” potrebbero essere utilizzati per migliorare il servizio, ovvero per riallenare il modello di intelligenza artificiale.
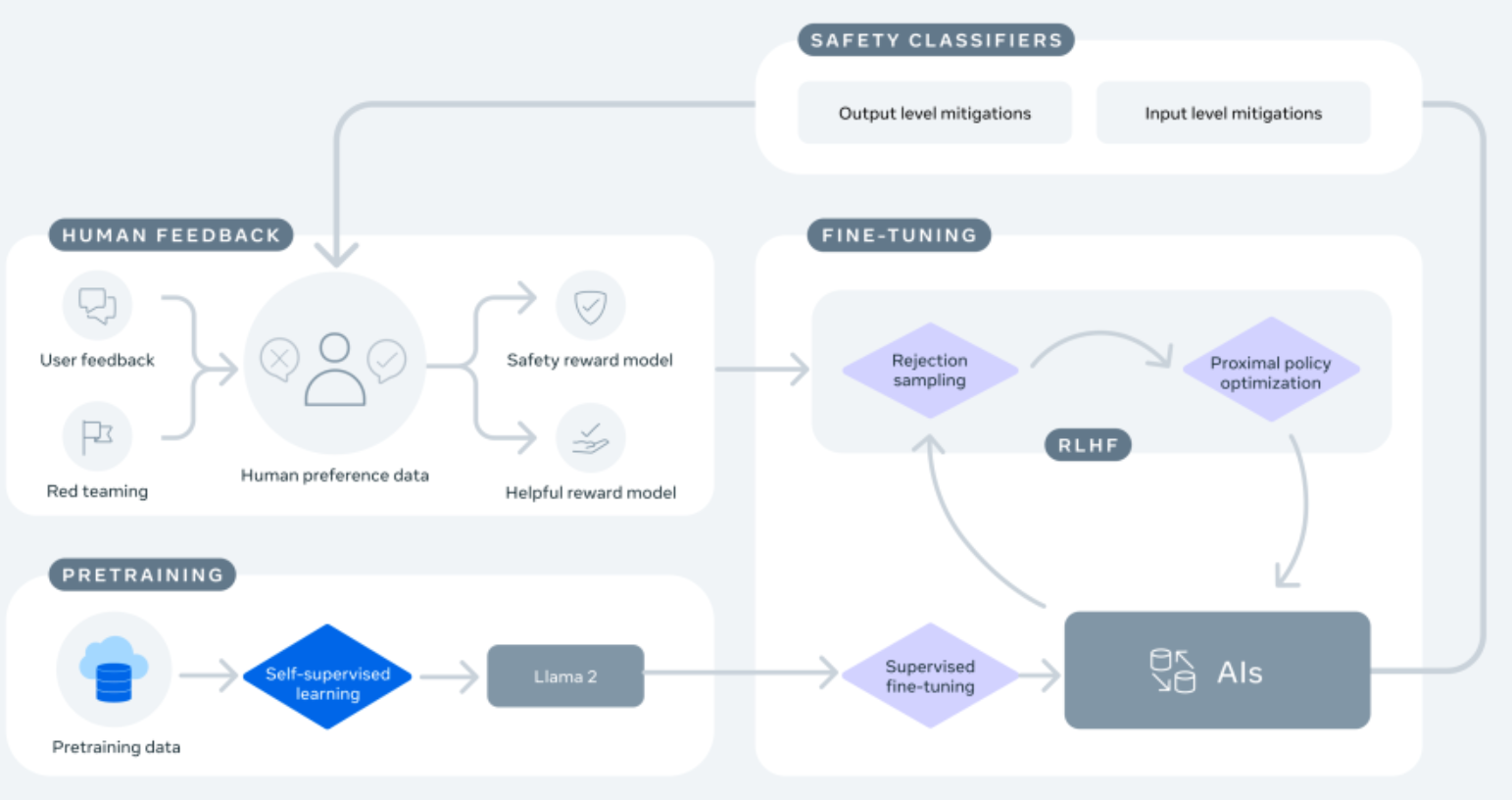
Come si può vedere, il blocco “Feedback umano” fornisce una parte essenziale dei dati per addestrare e perfezionare il modello. Ciò significa che le interazioni non sono solo l’obiettivo finale del servizio, ma sono anche l’aspetto critico per raccogliere dati per mantenerlo in evoluzione.
Domande aperte:
In base a ciò che ho appreso sul sito web di META, di seguito è l’elenco delle domande che ho formulato quando ho letto per la prima volta l’annuncio. Più sotto riporto le domande a cui è stata data risposta con le informazioni reperite sul sito web di META:
Q1) Quali sono i vantaggi per gli utenti finali nell’essere incentivati a interazioni più lunghe con chatbot di tipo umano?
Q2) Quali chat verranno usate per “migliorare il servizio”, tutte? Se sì, per quanto tempo? L’utente potrà rinunciare all’utilizzo della chat oppure è implicito che per evitare la raccolta dei dati l’unica opzione sarà quella di non sfruttare affatto il servizio?
Q3) Cosa succederebbe se tutti gli utenti di META cominciassero a chiedere all’assistente virtuale di cercare informazioni invece di sfruttare i motori di ricerca: ciò potrebbe avere un impatto sul libero mercato? Se sì, come e quali alternative avranno gli utenti finali e le nuove start-up?
Q4) Come fa META ad offrire tali servizi GRATUITAMENTE considerati gli ingenti costi per sviluppare i modelli e l’equipaggiamento Hardware e Software necessario per un servizio su scala globale?
Q5) Quali sono i rischi (comprese risposte indesiderate o conversazioni inappropriate) associati a tali servizi?
Domande risolte:
Le domande alle quali ho potuto trovare risposta sono le seguenti:
Q7) Quando le persone interagiscono su WhatsApp, Messenger o Instagram, le conversazioni vengono crittografate. Cosa accadrebbe in questo caso in cui l’interlocutore sarebbe lo stesso soggetto incaricato di crittografare gli scambi?
Come indicato sul sito Web META (e riportato nelle Figure 4a, 4b e 5), solo le interazioni dell’utente con il chatbot verranno utilizzate per riqualificare il modello. Pertanto, dovremmo aspettarci che tutte le domande o le conversazioni che avremo con il chatbot vengano condivise per migliorare il modello.
Q8) Quali misure (se presenti) sono in atto per mitigare i pericolosi effetti indesiderati?
In questo momento immagino 3 principali aree di perplessita’ legate a Privacy, Sicurezza e Mercato. È importante notare che le seguenti considerazioni non sono specificamente legate al prodotto META, ma all’idea generale di avere “chatbot” con cui interagire a livello generale, nel palmo delle mani dell’utente.
Perplessità sulla Privacy:
A marzo 2023, il Garante Privacy italiano ha bloccato ChatGPT, citando tra le cause la mancanza di trasparenza su come il sistema utilizzasse i dati delle interazioni degli utenti. Mentre è chiaro che META utilizzerà le informazioni degli utenti per ritraining del modello e migliorare il servizio, è ancora poco chiaro il livello di controllo (se esiste) che l’utente avrà sui propri dati dopo la raccolta. Il paragrafo unico che sono riuscito a recuperare sulla documentazione di META è riportato in Fig. 3b. Mentre la Fig. 3b fornisce consigli su come un utente potrà cancellare una chat, non c’è un’indicazione chiara di come i messaggi cancellati influenzeranno il modello. Ricorderà ciò che ha appreso da un’interazione dopo che l’utente l’ha cancellata? Quale controllo avrà l’utente sull’intero flusso di dati?
Quando si tratta di LLM (Large Language Models), lo stato attuale dell’arte afferma che le informazioni utilizzate per addestrare il modello non possono essere dimenticate a meno che il modello non venga riqualificato da zero senza le informazioni selezionate. Nonostante i legislatori abbiano già discusso del “diritto di dimenticare”, per il quale potete trovare ulteriori dettagli e proposte di soluzioni QUI, c’è ancora molto scetticismo. Sarebbe come cercare di rimuovere il sale da una salsa dopo che è stata cucinata e miscelata insieme: l’unico modo per essere sicuri che non ci sia sale è rifare la salsa da zero senza l’ingrediente.
Queste considerazioni diventano ancora più critiche se si considera che uno studio recente ha mostrato come i LLM siano capaci di catturare informazioni sul loro interlocutore anche quando non vengono esplicitamente espresse.
Perplessità sulla Sicurezza:
Recentemente, un uomo belga si è suicidato dopo aver chattato con un sistema di intelligenza artificiale. La macchina sembra aver influenzato l’utente a porre fine alla propria vita anziché suggerire di cercare aiuto. Puoi leggere di più QUI. L’uomo era padre di due figli e aveva un lavoro stabile, ma era preoccupato per il cambiamento climatico. Secondo sua moglie, suo marito ha iniziato a interagire con l’IA sull’argomento, ma anziché trovare speranza, sembrava aver perso fiducia. Una frase critica riportata in un articolo di Euronews menziona:
Consequently, he started seeing her as a sentient being and the lines between AI and human interactions became increasingly blurred until he couldn’t tell the difference.
Sebbene apprezzi gli sforzi di META per imparare da queste esperienze e adottare un approccio responsabile (come dichiarato QUI e confermato dalla Fig. 6), ho alcune preoccupazioni sulla complessità del compito che deve affrontare. Le macchine possono sfruttare il linguaggio umano per comunicare, ma (di nuovo) mancano della capacità di ragionamento che aiuterebbe a limitare questi casi. L’IA è in grado di generare testo ma non sa distinguere tra vero e falso o giusto e sbagliato. L’IA sa solo come costruire sequenze significative di parole più o meno correlate alle query originali. Da questo punto di vista, le parole possono essere utilizzate per esprimere un numero infinito di concetti. Più è grande il modello, più parole e concetti può generare. L’assistente virtuale di META sembra essere estremamente inclusivo e sfrutta questi modelli di linguaggio di grandi dimensioni. Tuttavia, non c’è alcuna garanzia né una stima del rischio che possa aiutare gli utenti finali a identificare il livello di maturità o affidabilità di questi sistemi.
L’aspetto più critico di quanto accaduto in Belgio non è legato all’incapacità dello strumento di filtrare domande delicate, quanto all’essere umano che si è identificato con lo strumento. L’empatia è una capacità umana. Non è accaduto solo in questo caso. Quante persone sviluppano una sorta di attaccamento al loro primo mezzo di trasporto? O casa? O profumo? O telefono? Tra gli esseri umani, l’empatia è un superpotere perché facilita il processo di costruzione delle relazioni. Ora questo superpotere potrebbe trasformarsi in una super-debolezza se ci porta a dimenticare la natura artificiale del sistema IA con cui potremmo interagire. È come se le auto fossero progettate con cruscotti che richiedono 3 mani ma singolo guidatore per essere manovrati correttamente: gli esseri umani sarebbero penalizzati dalla loro natura (solo 2 mani a disposizione) e il rischio di incidenti aumenterebbe. Il fatto che questi strumenti IA siano progettati per colmare le lacune percettive e confondere la linea tra ciò che è sintetico e ciò che è umano potrebbe generare più rischi che opportunità per interazioni sane nel lungo termine. In questo caso era un adulto, padre di due figli, con una carriera solida e focalizzato su un argomento specifico. Tuttavia, nessuno di questi aspetti ha aiutato ad evitare la tragedia. Cosa succederebbe se mettessimo adolescenti, con tutta la loro curiosità illimitata e poca esperienza nel gestire i limiti, dall’altra parte della chat con uno strumento basato su IA progettato appositamente per “essere amichevole”?
Esempi di risposte indesiderate o pericolose dai LLM sono molteplici e non si fermano alla triste storia belga. Di seguito sono riportati alcuni riferimenti:
Le guide alle piante commestibili generate dall’intelligenza artificiale (vendute su Amazon) incoraggiavano i lettori a raccogliere funghi velenosi. Gli investigatori online hanno trovato pericolose identificazioni errate. LINK
Una catena di supermercati neozelandese ha offerto un chatbot che crea ricette partendo da elenchi di ingredienti. Quando un utente gli ha chiesto cosa fare con acqua, ammoniaca e candeggina, ha offerto una ricetta per il gas letale cloramina. Successivamente il bot ha aggiunto alle ricette la clausola di esclusione della responsabilità: “Devi usare il tuo giudizio prima di fare affidamento o di realizzare qualsiasi ricetta prodotta da Savey Meal-bot”. LINK
Un chatbot fornito dalla National Eating Disorder Association ha dispensato consigli che potrebbero esacerbare i disturbi alimentari, hanno riferito gli utenti. Ad esempio, ha detto a un utente affetto da anoressia di continuare a perdere peso. L’organizzazione ha ritirato il bot. LINK
META ha rassicurato e continua a rassicurare sulle proprie procedure che includono fasi di test più avanzate ed estese, tuttavia mi chiedo se l’approccio tentativi-errori (trial-errors) sia abbastanza efficace per catturare l’intero spazio delle possibili risposte in cui il chatbot potrebbe risultare (pericolosamente) sbagliato. Questi dubbi sono ancora più amplificati se penso al di fuori del perimetro META e includo tutti i chatbot “generalisti”. Cosa accadrebbe se emergessero domande che non sono state precedentemente testate?
Per esempio, cosa accadrebbe se un’adolescente chiedesse sostegno privato per una presunta gravidanza? Qual è la probabilità di ricevere una risposta non dannosa dal chatbot? Queste informazioni verranno utilizzate per fornire pubblicità mirata?
Ad oggi, credo che questi chatbot forniscano il massimo valore se limitati a un contesto specifico (ad esempio vocabolari contestualizzati o gergo tecnico) per due motivi:
Lo spazio delle possibili risposte, comprese quelle sbagliate, è limitato a un contesto specifico
Sono lì per supportare le richieste degli utenti e non sono necessariamente sintonizzati per stimolare interazioni più lunghe. Non c’è quindi bisogno di “caratterizzazioni” degli strumenti
Perplessità sul Mercato (Libero):
Fornire “chatbot” o, in generale, servizi basati su LLM (Large Language Models) è estremamente costoso: richiede il costo di implementazione e manutenzione del software oltre a risorse di computazione dedicate e bollette energetiche elevate. Questo è stato evidenziato anche da Microsoft, che cerca alternative più economiche a ChatGPT e OpenAI, che ha a sua volta recentemente iniziato a cercare modi per risparmiare denaro.
Quindi, quale modello di business immagina META per ottenere un ritorno da questo investimento? Ecco la mia ipotesi:
META vede il suo valore nel possesso dei dati degli utenti che possono essere venduti per la pubblicità. Questa nuova funzionalità seguirà la stessa linea ma fornirà una visione molto più dettagliata delle preferenze dell’utente. Per le aziende interessate all’acquisto di informazioni e statistiche sulle preferenze degli utenti su un argomento o una categoria di interesse specifica, sarà come parlare con il nostro miglior amico per avvicinarsi il più possibile al nostro processo decisionale. Mi aspetto che questo possa causare un dirottamento importante del mercato, per due ragioni:
Se le persone inizieranno a chiedere agli assistenti di recuperare informazioni per loro, chi userà ancora i motori di ricerca? Il chatbot indirizzerà le risposte verso inserzioni a pagamento?
E per quanto riguarda il monopolio che META sarà in grado di costruire attorno ai dati degli utenti? Grazie a questi assistenti virtuali, META potrebbe guadagnare un vantaggio di mercato, rendendo estremamente difficile la vita di qualsiasi ipotetica startup o azienda concorrente. Pur riconoscendo il risultato come merito di una strategia vincente, mi chiedo se potrebbe essere anche un punto di discussione per i legislatori. Purtroppo non sono un esperto in materia quindi non posso che spingermi fino in fondo nel formulare la domanda.
Spunti di Riflessione:
Come ingegnere dell’IA, sono ben consapevole che i processi necessitano di tempo per migliorare. Sono entusiasta di vedere l’IA diventare utile e aiutare molte persone nella routine quotidiana. Tuttavia, non sono favorevole a accelerare tutto ad ogni costo per l’entusiasmo. Specialmente quando si tratta di IA, preferirei adottare un approccio cauto. Questa tecnologia è destinata ad aiutare gli esseri umani, e credo che le massime priorità dovrebbero concentrarsi sullo sviluppo di una maggiore consapevolezza tra gli utenti e garantire che siano in atto regolamentazioni adeguate prima di introdurre tecnologia avanzata nelle tasche di chiunque.
Se uniamo le preoccupazioni descritte sopra al modo in cui sono stati sviluppati questi assistenti virtuali, l’immagine sembra essere meno allettante.
Come dichiarato da META (Fig. 2), gli assistenti virtuali sono stati sviluppati per dare l’impressione che interagiremo con “persone familiari”. Questo si traduce nell’obiettivo di avvicinarsi il più possibile alla vita dell’utente per stimolare conversazioni intime e interazioni durature. Considero ciò estremamente pericoloso.
Per esempio, io amo le attività fai-da-te, ma ci sono strumenti come le motoseghe per i quali è richiesta una licenza o un corso di formazione prima di poterle usare. Dove non è necessaria una licenza, ci si aspetta il buon senso. Come nel caso di dispositivi elettrici e la loro vicinanza all’acqua. Abbiamo linee guida simili per questi strumenti AI? Perché possono generare effetti indesiderati, specialmente se utilizzati da bambini e non esperti. Forse introdurre una licenza o un piccolo corso di formazione su “come avvicinarsi all’IA quotidianamente” potrebbe già rappresentare una soluzione verso un approccio più responsabile per gli utenti finali.
Conclusioni e sommario:
Sintetizzando il quadro generale, ecco i punti chiave:
Gli assistenti virtuali sono progettati per stimolare conversazioni durature e confidenziali con te per massimizzare il tempo di interazione sulla piattaforma che ospita il servizio.
Le modalità di monetizzazione di META non sono chiare. Tuttavia, sappiamo che il servizio sarà gratuito per gli utenti finali nonostante sia estremamente costoso da offrire.
L’efficacia dei filtri e il livello di rischio associato al servizio per gli utenti finali non sono misurabili, ma differiscono da zero.
In conclusione, oltre a tutte le preoccupazioni condivise riguardo lo stato di scarsa consapevolezza della maggior parte degli utenti finali, rimango scettico sull’effettivo valore di “caratterizzare/umanizzare” questi assistenti virtuali.
Tuttavia, personalmente percepisco questo tentativo di “umanizzare gli strumenti” come un segnale d’allerta per non fidarsi degli assistenti a causa della presunta attitudine a “doppia-faccia”: progettati per essere i tuoi migliori amici da un lato, ma potenziali pettegoli “di lusso” per chiunque sia disposto a pagare per conoscere di più su di te.